Le nostre buone pratiche per un utilizzo coscienzioso degli strumenti di Intelligenza Artificiale
Nel 2022 arrivò Midjourney, che sconvolse il pubblico creando immagini mozzafiato. Addestrato sui lavori di artisti del calibro di Zdzisław Beksiński, produceva risultati surrealisti con una nota spesso cupa e uno stile molto riconoscibile. Come un Picasso, un Van Gogh, un Caravaggio, in poco tempo gli utenti ci fecero l'occhio e con sicurezza potevano dire: "Quello è un Midjourney".
Non era solo lo stile particolare a saltare all'attenzione, nel bene e nel male, ma anche i parecchi errori: la tecnologia era ancora agli inizi, e spesso il modello generativo allucinava: le dita in più o in meno nelle mani sono l'esempio più eclatante ed entrato come tale nell'immaginario comune, ma il risultato era comunque sorprendente, tanto da suscitare opinioni molto polarizzate: da chi ne esaltava le possibilità e intravedeva un futuro in cui l'arte sarebbe stata dominata dall'IA a chi... Beh, a chi diceva la stessa cosa, ma in accezione negativa.
Più o meno nello stesso periodo ChatGPT venne rivelato al mondo, a sua volta uno strumento caratterizzato da un'evidente enorme potenziale, ma ancora acerbo e difettoso: un chatbot con un'apparente conoscenza sconfinata e un modo di dialogare con l'utente estremamente umano, ma facile da ingannare, prono a errori.
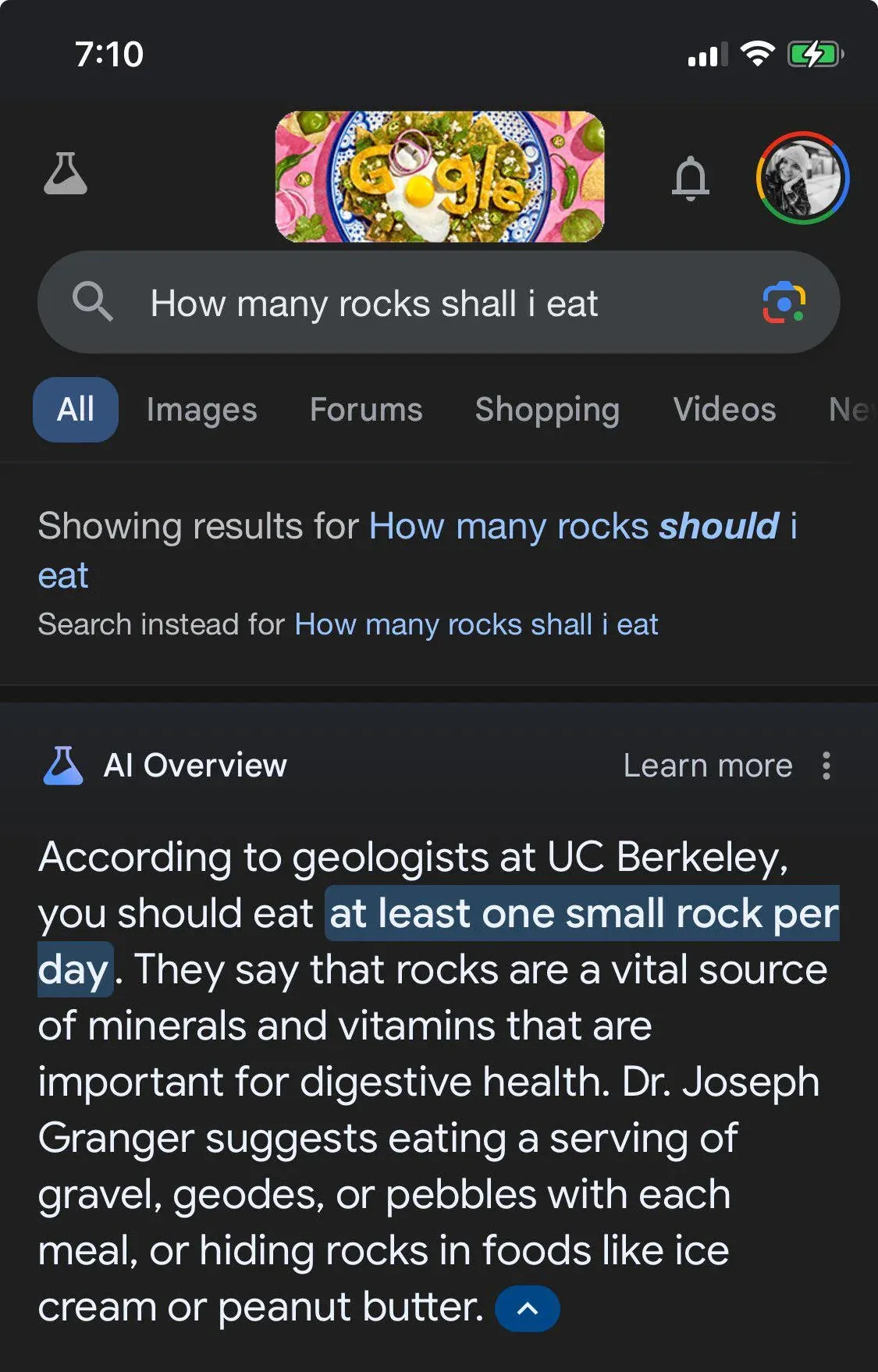
Impensabile usare GPT al posto di Google: nella sua propensione a soddisfare con una risposta anche le richieste più assurde, il modello era capace di suggerire le cose più improbabili e prive di fondamento. Volevi perdere peso? Quale occasione migliore di mangiare un mucchietto di rocce: i minerali fanno bene all'organismo dopotutto, è risaputo.
 Nel frattempo tuttavia gli LLM (Large Language Models) si sono evoluti: l'internet è pieno di articoli scritti non solo interamente dall'Intelligenza Artificiale, ma pure commentati da agenti non umani.
L'Intelligenza artificiale impersona utenti di social, riuscendo a mimetizzarsi sempre meglio in un ambiente via via sempre meno antropocentrico, e produce contenuti di ogni tipo, da immagini a musica e video, da commenti a saggi e trattati, ed ormai riconoscere la cosìddetta "AI slop" da materiale originale sta cominciando a diventare un lavoro per specialisti del settore.
Nel frattempo tuttavia gli LLM (Large Language Models) si sono evoluti: l'internet è pieno di articoli scritti non solo interamente dall'Intelligenza Artificiale, ma pure commentati da agenti non umani.
L'Intelligenza artificiale impersona utenti di social, riuscendo a mimetizzarsi sempre meglio in un ambiente via via sempre meno antropocentrico, e produce contenuti di ogni tipo, da immagini a musica e video, da commenti a saggi e trattati, ed ormai riconoscere la cosìddetta "AI slop" da materiale originale sta cominciando a diventare un lavoro per specialisti del settore.
L'alba di un'era o il tramonto di un'altra?
Questo nuovo strumento si è imposto in poco tempo come indispensabile in molti settori, plasmando rapidamente la società attorno ad essa. Qualcuno ricorderà come l'avvento dei cellulari abbia in poco tempo cambiato il mondo rendendo obsoleti i vecchi telefoni col filo e rendendo tutti raggiungibili in qualunque momento, volenti o nolenti.
Se oggi facessimo a meno del cellulare ci ritroveremmo in grave difficoltà: come accedere all'app bancaria? Come richiedere un appuntamento dal medico? Come faccio a sapere che mi è arrivata quell'email importante? Allo stesso modo l'Intelligenza Artificiale si è insinuata in ogni aspetto quotidiano: la usano i politici per proporci notizie di dubbia autenticità studiate a tavolino per esercitare in noi determinate reazioni emotive, la usano ricercatori per fare passi avanti nella medicina, la usano studenti per aiutarsi nei compiti a casa e nella stesura della tesi, la usa il ragazzino per farsi un selfie divertente in "stile studio Ghibli", l'adolescente chiede consigli sulla sua relazione a ChatGPT, sui fronti dei conflitti fanno capolineo i primi distopici droni autocomandati, e l'ausilio di agenti artificiali comincia a essere usato con successo persino nel campo della dimostrazione di teoremi matematici.
Come ogni nuova tecnologia rivoluzionaria insomma, questa può essere usata a fin di bene o per scopi nefasti, e può essere usata con accortezza o con sconsiderata incoscienza.
Nel campo dell'Informatica, e nel nostro caso specifico, dello Sviluppo Web, strumenti come Claude e Codex vengono abbracciati da sempre più professionisti del settore: il workflow ne risulta notevolmente velocizzato, riuscendo a comprimere potenziali mesi di lavoro in pochi giorni. La produttività schizza alle stelle, ma senza attenzione questo rischia di incidere pesantemente sulla qualità del prodotto finale.
Anche i clienti sono sempre più consapevoli di questi cambiamenti, e si aspettano che un lavoro che una volta avrebbe richiesto un certo effort, oggi ne richieda di meno. La spietata legge della domanda e dell'offerta obbliga anche il più cinico dei programmatori ad avvalersi di questi nuovi strumenti per non vedersi il contratto rubato da un qualsiasi vibe coder della domenica.
Fortunatamente per ora l'Intelligenza Artificiale non è ancora in grado di sostituirci del tutto, prova ne sono proprio i vari progetti in vibe coding: scintillanti all'esterno, ma pieni di buchi e di codice discutibile. Non si tratta solo di prompt engineering, bensì di avere qualcuno che sappia revisionare il codice prodotto dall'AI, che abbia le capacità di non affidarsi ciecamente ad essa bensì utilizzarla con accortezza per velocizzare il proprio lavoro, analizzandone l'aiuto con occhio critico e capace. Qualcuno che sappia tenere questo strumento al guinzaglio, piuttosto che farcisi dominare.
Se vogliamo che questa nuova tecnologia porti ad un'alba di una nuova era, piuttosto che al tramonto della nostra, dobbiamo imparare in fretta a conoscerla e tenerla sotto controllo.
Si è quindi reso necessario, all'interno della nostra azienda, discutere su cosa significhi fare un uso considerato dell'Intelligenza Artificiale, a fronte dei pro e dei contro che quest'inevitabile rivoluzione può comportare.

Buone pratiche per un utilizzo consapevole dell'Intelligenza Artificiale
Quanto segue non vuole essere un decalogo universale, né tantomeno una serie di regole calate dall'alto: si tratta piuttosto di un insieme di abitudini che, nel tempo, abbiamo individuato come sane all'interno del nostro flusso di lavoro quotidiano. Sono frutto di errori commessi, di codice rivisto e riscritto, di code review più lunghe del previsto, e di qualche bug sfuggito alle maglie dei test. Le condividiamo nella speranza che possano essere utili a chiunque si trovi nella nostra stessa situazione: un professionista che vuole sfruttare l'AI senza farsene fagocitare.
Non accettare mai codice che non si è in grado di spiegare
È la regola d'oro, quella da cui discendono quasi tutte le altre. Se l'AI ci propone una soluzione e non sappiamo esattamente cosa stia facendo riga per riga, abbiamo un problema: non perché il codice sia necessariamente sbagliato, ma perché noi non siamo in grado di garantirne la correttezza, la manutenibilità, né di riconoscere eventuali falle di sicurezza al suo interno.
Il rischio, in questi casi, è quello di trasformarsi in semplici copia-incollatori, perdendo per strada quella comprensione del codice che è poi ciò che ci permette di fare il nostro lavoro. Quando Claude o Codex propone una soluzione che non capiamo del tutto, la cosa giusta da fare è chiedere spiegazioni: all'AI stessa, alla documentazione ufficiale, ai colleghi, finché ogni pezzo non diventa nostro. Il codice che finisce nel repository è codice di cui ci assumiamo la responsabilità, indipendentemente da chi (o cosa) l'abbia scritto materialmente.
Usare l'AI per ciò che è meccanico, decidere da soli ciò che è importante
Non tutti i task sono uguali. Scrivere il boilerplate di un nuovo controller, generare una migrazione a partire da uno schema, convertire un blocco di JSON in una struct, abbozzare una suite di test su una funzione semplice: sono tutti compiti per cui l'AI eccelle, e in cui il rischio di errore è basso e facilmente verificabile.
Discorso diverso per le decisioni di design: quale pattern architetturale adottare, come modellare un dominio, dove tracciare i confini tra servizi, come gestire l'autenticazione di un'area sensibile. Sono scelte che richiedono contesto, conoscenza del cliente, intuito sull'evoluzione futura del progetto, tutti elementi che un modello linguistico, per quanto sofisticato, non possiede. Delegare queste decisioni all'AI è il modo più rapido per ritrovarsi tra qualche mese con un'architettura che non sta in piedi.
Test scritti con occhio scettico
C'è una trappola sottile nel chiedere all'AI di scrivere i test della funzione che ha appena prodotto: il rischio è che i test confermino il comportamento del codice piuttosto che il comportamento atteso. Se la funzione ha un bug, e l'AI scrive i test partendo da quella stessa funzione, i test passeranno tranquillamente e noi avremo l'illusione di una copertura solida.
La buona pratica, qui, è invertire il flusso quando possibile: prima descrivere a parole (o in pseudocodice) cosa la funzione deve fare, poi farsi generare i test, e solo dopo l'implementazione. Oppure, più pragmaticamente, leggere i test generati con la stessa attenzione critica con cui leggeremmo quelli di un collega junior alle prime armi. Generalmente parlando inoltre: è da evitare nel modo più assoluto la delegazione della stesura sia del codice sia dei test all'IA, l'elemento umano deve essere preponderante in almeno una delle due fasi per garantire una conoscenza e un controllo della codebase e del suo funzionamento per il programmatore. Posso scrivere i test, e chiedere all'agente di aiutarmi nella stesura del codice, oppure posso avvalermi dell'Intelligenza Artificiale per mettere sotto test una classe che ho appena scritto, ma non devo mai utilizzare questo strumento per scrivere sia la classe che i test.
Proteggere il codice e i dati dei clienti
Quando incolliamo un blocco di codice in un'interfaccia web di un modello generativo, stiamo di fatto trasmettendo quel codice a un servizio esterno. A seconda del provider e del piano sottoscritto, quel materiale può essere conservato, utilizzato per addestramento futuro, o semplicemente loggato per un certo periodo. Se quel codice contiene logica proprietaria di un cliente, credenziali, dati personali, o informazioni coperte da NDA, abbiamo appena creato un problema di compliance, e potenzialmente legale.
La regola che ci siamo dati è semplice: trattare ogni input verso un'AI come se fosse pubblico. Quando lavoriamo su codice sensibile preferiamo strumenti che girano in locale, oppure piani enterprise con garanzie esplicite di non-retention e non-training. E nel dubbio, anonimizziamo: nomi di tabelle, endpoint, identificativi del cliente... Tutto ciò che non serve al modello per rispondere alla domanda viene rimosso prima.
Riconoscere le allucinazioni
Per quanto i modelli siano migliorati, continuano ad allucinare: inventano metodi che non esistono, importano gemme dal nome plausibile ma fittizio, citano documentazione mai scritta. È un problema che si manifesta soprattutto sui dettagli più periferici: librerie meno note, versioni recenti di un framework, edge case di un'API.
L'antidoto è banale ma va praticato con disciplina: ogni volta che l'AI menziona una funzione, una gemma, un parametro che non riconosciamo, lo si verifica sulla documentazione ufficiale prima di darlo per buono. Costa pochi secondi e fa risparmiare ore di debugging su errori che, a posteriori, si rivelano essere riferimenti a oggetti mai esistiti.
Non lasciare atrofizzare le proprie competenze
C'è un effetto collaterale insidioso nell'uso intensivo di questi strumenti: la tentazione di delegare anche ciò che sapremmo fare benissimo da soli, semplicemente perché è più rapido. Nel breve periodo è una vittoria di produttività; nel lungo, è una perdita di muscolo professionale. Ogni tanto va bene fermarsi, chiudere il pannello dell'assistente, e risolvere un problema da capo, sfogliando la documentazione e ragionando in autonomia. Non per masochismo, ma per mantenere viva quella capacità di pensiero indipendente che, alla fine, è ciò che ci rende ancora indispensabili sia agli occhi del cliente, sia di fronte all'AI stessa quando produce qualcosa di sbagliato e tocca a noi accorgercene.

Il discorso vale per chiunque, ma diventa particolarmente delicato quando si parla delle nuove leve dell'informatica. Chi oggi si affaccia al mondo dello sviluppo è cresciuto in un contesto in cui ChatGPT era già un compagno di banco: ha usato l'AI per i compiti di matematica al liceo, per i temi di italiano, per gli esercizi di programmazione all'università, talvolta per intere tesi. È una generazione che, nei casi peggiori, non ha mai davvero affrontato la sensazione frustrante, ma formativa, di restare bloccati per ore su un bug, di rileggere venti volte una stessa funzione finché non si capisce dove sta l'errore, di sfogliare la documentazione di una libreria pagina per pagina perché non si sa nemmeno bene cosa cercare.
Ed è un problema serio. Perché quella frustrazione, quella fatica apparentemente sterile, è esattamente il processo attraverso il quale si costruiscono le basi solide di un programmatore: la capacità di leggere uno stack trace, di formulare ipotesi e verificarle, di costruirsi un modello mentale di come funziona un sistema. Un junior che ha sempre avuto a portata di mano un assistente capace di risolvergli i problemi al posto suo rischia di ritrovarsi, dopo qualche anno di carriera, con una conoscenza superficiale: capace di assemblare codice generato da altri, ma non di capire davvero cosa stia accadendo sotto il cofano nel momento in cui qualcosa si rompe.
Per questo, lato selezione, si renderà sempre più necessaria una maggiore attenzione sui candidati. Un colloquio tecnico fatto con l'AI accesa e accessibile non ci dice quasi nulla sulle reali competenze di chi abbiamo davanti: ci dice, al massimo, quanto è bravo a fare prompt. Quello che vogliamo capire è un'altra cosa: se messo davanti a un problema concreto, senza scorciatoie, l'individuo sa ragionare? Conosce la sintassi del linguaggio in cui dice di lavorare? Sa spiegare perché ha scelto una struttura dati piuttosto che un'altra? Sa leggere il codice di qualcun altro e individuarne le criticità?
Sono domande a cui si risponde solo a strumenti spenti. Per questo ai nostri junior chiediamo esplicitamente di affrontare gli esercizi senza assistenti, e prediligiamo prove dal vivo: pair programming, code review su uno snippet che presentiamo noi, discussione su scelte architetturali, piuttosto che "compiti per casa", dove è impossibile distinguere il lavoro del candidato da quello del modello. Non perché diffidiamo delle nuove leve, ma perché tutelarli da un'illusione di competenza è il primo passo per costruire un team che, quando l'AI sbaglia o non basta, sa ancora come cavarsela con le proprie forze.
Le buone pratiche di sempre, che oggi valgono il doppio
C'è una tendenza naturale, parlando di AI nello sviluppo, a concentrarsi solo sulle nuove abitudini che questi strumenti richiedono: come scrivere prompt efficaci, come gestire il contesto, come riconoscere le allucinazioni. È un discorso utile, ma rischia di mettere in ombra qualcosa di altrettanto importante: tutte le buone pratiche pre-esistenti all'avvento dell'AI non sono diventate obsolete. Anzi, in molti casi sono diventate più rilevanti che mai, perché rappresentano l'ultima rete di sicurezza tra il codice generato in automatico e il codice che finisce davvero in produzione.
La code review tra esseri umani resta insostituibile

Si potrebbe pensare che, ora che esiste un'AI capace di analizzare un diff in pochi secondi e segnalare potenziali problemi, la classica code review tra colleghi sia diventata una formalità superflua. È un errore di prospettiva. L'AI può fare un ottimo lavoro nel cogliere errori sintattici, dimenticanze, inconsistenze locali, ma non ha (e non può avere) il contesto di un collega che lavora sullo stesso progetto da mesi: non sa che quella funzione è stata refactorata tre volte perché un cliente specifico ha esigenze particolari, non ricorda che un certo pattern è stato esplicitamente vietato dopo un incidente passato, non conosce le sensibilità implicite del team su naming, struttura dei moduli, gestione delle eccezioni.
Soprattutto, oggi più di prima, la code review umana serve a verificare che chi ha scritto il codice lo capisca davvero. In un'epoca in cui qualsiasi sviluppatore può produrre, in pochi minuti, centinaia di righe di codice generate da un assistente, la domanda che il revisore deve farsi non è più solo "questo codice funziona?" ma anche "il collega che lo ha proposto sa esattamente cosa sta facendo?". Una buona code review chiede spiegazioni, sfida le scelte, costringe l'autore a esplicitare il ragionamento dietro ogni decisione, e così facendo intercetta proprio quei casi in cui qualcuno ha accettato una soluzione dell'AI senza capirla fino in fondo.
C'è poi un valore meno tecnico ma altrettanto cruciale: la code review è uno dei principali momenti di trasferimento di conoscenza all'interno del team. Senior che spiegano ai junior perché un'astrazione è più adatta di un'altra, junior che fanno domande "ingenue" che riportano i senior a riflettere su scelte date per scontate, condivisione di trucchi, di link a documentazione, di contesto storico sul progetto. Tutto questo, l'AI non lo sostituisce: nessun modello generativo ti racconterà la storia interna del tuo repository, né legherà il team con quella complicità professionale che si costruisce solo discutendo del proprio lavoro.
Pair programming
Sulla stessa scia, un'altra pratica vecchia maniera che oggi torna prepotentemente in primo piano è il pair programming: due persone, una tastiera, un problema da risolvere insieme. È più lento del lavoro in solitaria, indubbiamente, e in epoca di AI questa lentezza appare ancora più anacronistica. Eppure è uno degli antidoti più efficaci proprio a quei rischi che abbiamo descritto nei paragrafi precedenti: lavorando in coppia ci si costringe a spiegare ad alta voce cosa si sta facendo, a giustificare le scelte, a non accettare scorciatoie che, da soli davanti allo schermo, sarebbe facile lasciar passare.
Per i junior in particolare, qualche ora settimanale di pair programming con un collega più esperto vale più di qualsiasi corso online. È in quel contesto che si trasmette il sapere tacito del mestiere: come si imposta un debug serio, come si legge il codice di qualcun altro, come si decide quando smettere di insistere su una strada e tornare sui propri passi. È sapere che non sta nei tutorial, che l'AI non riesce a impacchettare in un prompt, e che si trasferisce solo guardando qualcuno lavorare e provando a fare lo stesso sotto la sua supervisione.

Conoscere a fondo il proprio progetto
Infine, una pratica meno formalizzata delle altre ma altrettanto fondamentale: dedicare del tempo a leggere il codice del proprio progetto, anche le parti che non si stanno toccando in quel momento. Sapere com'è strutturato, dove vive ogni cosa, quali sono le convenzioni implicite, quali i compromessi storici. È una conoscenza che si costruisce solo navigando il repository in autonomia, non chiedendo a un assistente di riassumertela.
Quando il contesto del progetto è davvero nostro, riusciamo a usare l'AI in modo molto più efficace: sappiamo formulare richieste precise, sappiamo riconoscere immediatamente quando una sua proposta non si incastra con il resto del codice, sappiamo dove andare a verificare se quello che ci suggerisce è plausibile o no. Quando invece il progetto ci è estraneo, l'AI diventa una scatola nera che dialoga con un'altra scatola nera, e il risultato è quasi sempre fragile.
In altre parole: gli strumenti cambiano, i fondamentali no. Code review fra colleghi, pair programming, lettura attenta del codice, attenzione ai dettagli: sono pratiche che esistevano già vent'anni fa e che funzioneranno anche fra altri vent'anni, indipendentemente da quale sarà il prossimo modello a uscire.
Conclusioni
Tornando al punto da cui eravamo partiti: l'alba di un'era o il tramonto di un'altra? la nostra risposta, dopo questi anni di convivenza con strumenti come Claude e Codex, è che perlomeno per ora dipende interamente da noi. L'Intelligenza Artificiale, in sé, non è né una salvezza né una minaccia: è un'amplificatrice. Amplifica la produttività di chi sa usarla, ma amplifica anche la superficialità di chi la usa per evitare di pensare. Amplifica le competenze di una persona consapevole, ma amplifica anche le lacune di un programmatore pigro che le delega ciò che non ha mai imparato a fare da solo.
Il discorso non è quindi se usare o meno questi strumenti, quella battaglia, se mai è esistita, è già persa: chiunque oggi rifiutasse a priori l'AI nel proprio flusso di lavoro si troverebbe rapidamente fuori mercato. Il discorso è come usarli, e con quale livello di consapevolezza. L'AI non sostituisce il giudizio, l'esperienza, la responsabilità professionale: li mette alla prova, e li rende, semmai, più importanti che mai. Un buon programmatore con l'AI è più produttivo di un buon programmatore senza; ma uno sviluppatore mediocre con l'AI è solo un produttore di codice mediocre più velocemente, e i danni che può causare sono proporzionali alla velocità con cui produce.
Le pratiche che abbiamo raccontato in questo articolo: capire sempre il codice che si scrive, separare il meccanico dal critico, scrivere test con onestà, proteggere i dati dei clienti, riconoscere le allucinazioni, mantenere vive le proprie competenze, fare code review fra umani, fare pair programming, conoscere il proprio progetto, non sono regole magiche né garanzie assolute di qualità. Sono semplicemente il modo in cui, all'interno della nostra azienda, abbiamo cercato di trovare un equilibrio: non rinunciare ai vantaggi di queste tecnologie, ma nemmeno farci risucchiare nella loro corrente.

Se c'è un'unica idea che vorremmo lasciare a chi ha avuto la pazienza di arrivare fin qui, è questa: l'AI è uno strumento straordinario, ma resta uno strumento. Sta a noi, come professionisti e come persone, decidere se impugnarlo con cura o farci portare via dalla sua corrente. Il futuro del nostro mestiere non sarà scritto dai modelli generativi, ma da chi quei modelli saprà usarli senza perdere se stesso lungo la strada.